

Retour d’expérience sur le tracing, en utilisant OpenTelemetry avec la solution Jaeger.
Contexte
Cet article est un retour d’expérience sur un POC que j’ai effectué sur le tracing, troisième pilier de l’Observabilité, ainsi que sur les données de télémétries. Le but étant de montrer comment les données de télémétries permettent d’analyser plus facilement les requêtes dans une application microservices.
En effet, c’est suite à une conférence de Vincent Behar au Devoxx 2022, que je me suis intéressé par la suite à OpenTelemetry, et au tracing en général.
En première partie de cet article, je souhaitais partager les notions que j’ai pu apprendre tout au long de ce POC, sur OpenTelemetry, et le tracing en général.
La deuxième partie sera un retour d’expérience sur l’installation de Jaeger en local et sur un cluster Kubernetes, ainsi que des outils que j’ai utilisés pour déployer et tester cette solution.
Piliers de l’observabilité
Tout d’abord, avant d’aborder le POC en lui-même, je voudrais revenir sur 3 piliers de l’observabilité, que sont les logs, les metrics et enfin le tracing qui est le sujet qui nous intéresse.
Les logs d’événements vont permettre d’enregistrer l’activité d’une application, et se définissent par un contexte et une date d’écriture. Elles sont faciles à générer et la plupart des langages ont déjà des librairies pour les implémenter facilement dans une application à microservices. Le fait de générer beaucoup de logs dans un système peut avoir des impacts sur les performances, et les coûts de facturation générés, en fonction de la plateforme qui héberge l’application, d’où l’importance à donner sur les logs qu’on souhaite écrire.
Ensuite viennent les metrics, au format numérique, elles vont nous permettent d’analyser le comportement et les performances d’un service. Celles-ci sont peu gourmandes au niveau performance système, ce qui permet facilement de les interroger, dans une application telle que Grafana par exemple.
Enfin, le tracing, le 3ᵉ pilier de l’observabilité, représente une série d’événements effectuée par une request, lorsque celle-ci parcourt plusieurs services (ou spam) dans une application. Utilisé ensemble avec des logs d’événements, cela permet d’avoir une meilleure visibilité de ce qui se passe dans une application microservices.
Tout comme les metrics, elles consomment moins que les logs, et on pourra utiliser Jaeger par exemple pour visualiser ces données.
Qu’est-ce que OpenTelemetry ?
OpenTelemetry est un framework d’Observabilité Open Source, issue du CNCF (Cloud Native Computing Foundation). Ce framework fusionne les anciens projets historiques OpenCensus et OpenTracing, et fournit une collection d’outils, d’API et de SDK qui vont nous permettre de collecter les metrics, les traces ou les logs que nous avons vus précédemment.
Ce projet va permettre d’instrumenter notre application, avec des données de télémétrie standardisées, afin de les envoyer au backend Jaeger, que j’ai utilisé pour ce POC.
Par exemple, en Java, OpenTelemetry fournit un dépôt Core, contenant un SDK et une API pour l’implémenter à la main dans notre application, ainsi que le dépôt Instrumentation pour que cela se fasse de manière automatique via un agent.
Toutes ces données de télémétries vont nous permettre par la suite de les monitorer afin d’analyser plus facilement la root cause d’un bug applicatif, de visionner les dépendances de services ou d’optimiser les performances d’une application distribuée.
Qu’est-ce que Jaeger ?
Inspiré de OpenZipkin, Jaeger est un projet open-source concurrent de SigNoz, qui va nous aider à monitorer les données de tracing standardisées par OpenTelemetry, pour les analyser plus facilement dans un tableau de bord.
Ce projet est constitué de plusieurs composants, dont chacun d’eux est disponible dans une image Docker. Le composant jaeger-all-in-one quant à lui contient l’ensemble de ces composants.
- Le premier composant est l’agent, daemon qui écoute les spans (service applicatif) afin de les envoyer au collector.
- Le collector va récupérer les traces envoyées par les agents, afin de les indexer et les stocker. Ce composant peut être pluggé avec Cassandra, Elasticsearch ou Kafka.
- Enfin, le composant Query va permettre d’interroger et visualiser les données de télémétries dans un tableau de bord, en se basant sur les données récupérées par le collector.
On pourrait également parler du composant Ingester, qui est un service permettant de lire les données sur Kafka, afin de les envoyer dans une autre backend comme Cassandra ou Elasticsearch.
Application de démo Jaeger en local
Pour commencer ce POC, je suis parti de la documentation officielle de Jaeger pour tester la solution en local sur mon poste, en me basant sur l’application Java Springboot de démo springboot_jaeger_tutorial.
Bien documentée, j’ai trouvé que cette solution est une bonne porte d’entrée pour comprendre le fonctionnement et l’architecture de Jaeger, sans avoir besoin d’une application distribuée déployée dans un environnement Kubernetes.
Première étape : installation des composants Jaeger
Dans un premier temps, l’idée était de déployer tous les composants de base de Jaeger, c’est-à-dire l’Agent, le Collector et le Query. Pour cela, j’ai effectué cette commande, en ayant préalablement installé Docker sur mon poste Ubuntu :
docker run -d --name jaeger \
-e COLLECTOR_ZIPKIN_HTTP_PORT=9411 \
-p 5775:5775/udp \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 9411:9411 \
-p 14268:14268 \
-p 14250:14250 \
-p 16686:16686 \
jaegertracing/all-in-one:1.37Comme on peut le voir, on utilise l’image Docker jaegertracing/all-in-one en version 1.37.0, qui contient tous les composants Jaeger mentionnés au-dessus.
Plusieurs ports sont exposés sur le host, nécessaires pour tester cette démo.
Les 4 premiers ports (5775, 6831, 6832, 5778) correspondent à l’agent Jaeger, le composant qui permet de récupérer les données de télémétries de l’application distribuée.
Les 3 suivants (9411, 14268, 14250) sont des ports exposés au host et proviennent du composant collector. Le port http 9411 expose une api Zipkin, et permet d’interroger ce collecteur afin de récupérer les données de tracing, ou d’envoyer un span directement en POST.
Exemple d’un Swagger permettant de consommer cette API : https://zipkin.io/zipkin-api/
Enfin, le dernier port HTTP 16686, correspond au composant Query et va nous permettre d’accéder au tableau de bord de Jaeger afin de consulter facilement les données de télémétries.
La variable d’environnement COLLECTOR_ZIPKIN_HTTP_PORT, désactivé par défaut, et définit sur le port 9411 pour cette démo, et va permettre d’exposer l’API de Zipkin sur le port 9411, pour la consommer avec le tableau de bord de Swagger.
On pourrait également ajouter la variable d’environnement SPAN_STORAGE_TYPE (en memory par défaut), qui définit le type de stockage à utiliser :
- memory
- cassandra
- elasticsearch
- Kafka
- Badger (en expérimental depuis Jaeger 1.9)
Deuxième étape : installation de l’application de démo
Dans un deuxième temps, j’ai installé l’application de démo sur mon poste en me basant sur ce projet : https://github.com/egoebelbecker/jaeger-tutorial.git.
Pour cela j’ai généré un Dockerfile de cette application, ce qui nécessitait d’installer openjdk-11 ainsi que Gradle sur mon poste.
Pour l’installation de Gradle en version 6.8.3, et permettre la compatibilité avec la version de Springboot utilisée par ce projet, cela demandait un peu plus de configuration, car cela se fait de façon manuelle.
La dernière étape a consisté à containerisé cette application Springboot à partir de l’image Docker construite. J’ai utilisé cette commande afin d’exposer l’application sur le port 8080.
docker run \
--name springboot_jaeger_tutorial \
-p 8080:8080 \
-e JAEGER_AGENT_HOST="127.0.0.1" \
-e JAEGER_AGENT_PORT=6831 \
springboot_jaeger_tutorialAu final, je pense que ça aurait été plus simple d’installer Gradle avec Docker en utilisant comme volume le dossier du tutoriel, ça m’aurait évité d’effectuer toutes les commandes qu’on a pu voir au-dessus.
Tests sur l’application de démo
Une fois les composants Jaeger et l’application de démo installés sur mon poste, j’ai pu jouer avec le tableau de bord et l’API Zipkin pour comprendre un peu mieux le fonctionnement du tracing.
En naviguant dans le tableau de bord, on peut effectuer une recherche des traces de l’application de démo en les filtrant par service (application qui est enregistrée dans Jaeger), opération (request envoyée à l’application), ainsi que par tags ou période de temps.
Pour résumer, une trace se compose d’un identifiant, et d’un ou plusieurs spans. Un span représente une opération (request) dans une couche applicative, et se définit par des tags, ainsi qu’une période de temps.
Enfin, un tag représente une information de la request, telle que le status code (200 généralement), une url ou un verbe (GET).
Exemple au format JSON :
{
"data": [
{
"traceID": "1234",
"spans": [
{
"traceID": "1234",
"spanID": "5678",
...
"tags": [
...
{
"key": "http.method",
"type": "string",
"value": "GET"
},
{
"key": "http.status_code",
"type": "int64",
"value": 200
}
],
"logs": [],
"processID": "p1",
"warnings": null
}
],
"processes": {
"p1": {
"serviceName": "jaeger-query",
"tags": [
{
"key": "client-uuid",
"type": "string",
"value": "..."
},
...
]
}
},
"warnings": null
}
],
"total": 0,
"limit": 0,
"offset": 0,
"errors": null
}C’est avec ce tag qu’on va pouvoir rechercher par la suite les requests en erreur, en filtrant les traces avec un status code correspondant à une erreur serveur par exemple.
En utilisant les librairies fournies par OpenTelemetry dans notre application, on peut alors injecter des tags spécifiques afin de faciliter la recherche de traces dans le tableau de bord.
POC Jaeger avec Istio dans un cluster k8s
La deuxième partie du POC à consister à m’intéresser à l’installation de la solution Jaeger dans un cluster Kubernetes.
Pour cela, j’ai utilisé un petit serveur NUC avec la distribution Ubuntu Server, et opté pour la solution microk8s, qui me paraissait intéressante pour avoir un cluster Kubernetes de test et effectuer le déploiement d’une application microservice.
Cluster Kubernetes avec Microk8s
Pour simplifier et industrialiser l’installation de microk8s, j’ai créé un playbook Ansible et utiliser le role istvano.microk8s fournit par la communauté, qui installe cet outil avec snap. Cela m’a permis de configurer finement les plugins microk8s nécessaires à ce POC, et d’accéder au tableau de bord Kubernetes,
Pour le besoin de ce POC, j’ai activé les modules suivants : dns, dashboard, ingress, host-access, istio et jaeger.
Pour avoir un loadbalancer de disponible, et accéder aux applications déployées dans le cluster via une IP, j’ai activé le plugin metallb directement sur le serveur en le configurant avec une ip disponible sur mon réseau local. Cela aurait pu être configuré également dans le playbook Ansible.
Pour accéder au tableau de bord Kubernetes plus facilement, j’ai modifié le service kubernetes-dashboard afin de changer le type de ressource de ClusterIP à NodePort. Le port décrit dans ce service me permettait d’accéder à ce dashboard à partir de l’IP où est installé Microk8s. J’ai utilisé cette commande pour effectuer ceci :
kubectl edit service kubernetes-dashboard --namespace=kube-systemPour accéder à ce tableau de bord, il est nécessaire de générer un jeton sur le serveur Kubernetes, qui sera demandé pour se connecter.
token=$(kubectl -n kube-system get secret | grep default-token | cut -d " " -f1)
kubectl -n kube-system describe secret $tokenEnfin, afin de pouvoir visualiser les ressources Kubernetes avec l’outil k9s, j’ai copié la configuration de Kubernetes dans le home de mon utilisateur.
Et une fois le cluster Kubernetes installé et configuré, j’en ai profité également pour ajouter quelques utilitaires sur ce serveur, tels que k9s, kubectx ou kubens. L’outil kubectx permet de changer facilement de contexte dans un cluster alors que kubens permet de changer le namespace par défaut lorsqu’on interroge les ressources, avec la commande kubectl par exemple.
Service Mesh avec Istio
Après avoir mis en place le cluster Kubernetes, et installé tous les outils, je me suis intéressé à la manière dont j’allais déployer la solution Jaeger.
J’ai opté alors pour le service Mesh Istio, ce qui va permettre d’injecter automatiquement des données de télémétrie et de les visualiser dans le tableau de bord de Jaeger.
Pour rappel, le service Mesh, qui se base sur le pattern d’architecture sidecar, est une couche qui permet de contrôler la façon dont différents éléments d’une application partagent des données les uns avec les autres.
Pour installer ce service Mesh Istio dans le cluster Kubernetes, j’ai repris le playbook Ansible et activé le plugin Istio. J’ai activé également le plugin Jaeger afin de déployer les ressources Kubernetes de Jaeger dans le cluster.
Enfin, pour bénéficier de l’injection automatique des données de télémétries, j’ai activé cette fonctionnalité dans le namespace default, en utilisant cette commande :
kubectl label namespace default istio-injection=enabledDéploiement de l’application de démo
Il nous reste plus qu’à déployer l’application de démo dans le namespace default, afin d’avoir accès aux données de télémétries dans le tableau de bord Jaeger.
Ceci se fait en ayant préalablement téléchargé le projet Istio, qui contient les ressources k8s de la démo bookinfo à déployer dans le cluster Kubernetes.
Exemple :
cd istio-1.14.3/
kubectl apply -f samples/bookinfo/platform/kube/bookinfo.yaml
kubectl apply -f samples/bookinfo/networking/bookinfo-gateway.yamlCi-dessous les ressources de type pod et service qui sont déployés sur le cluster :
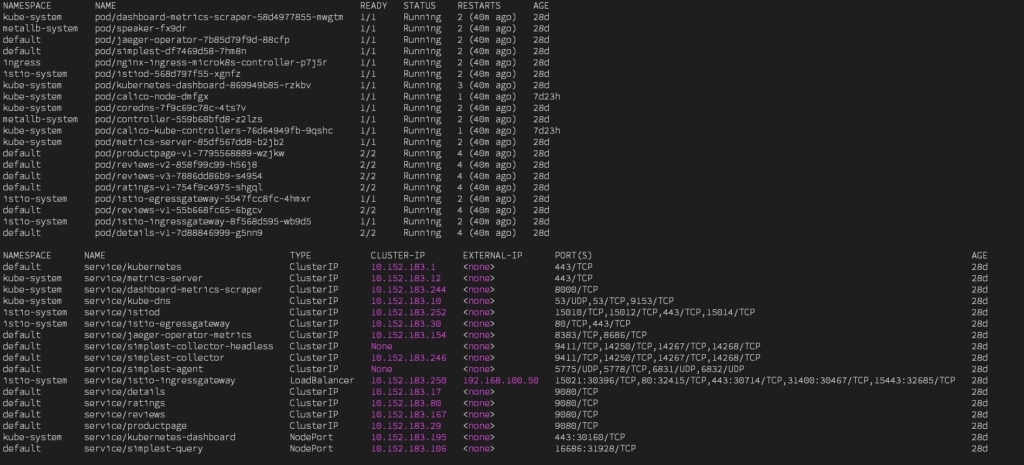
Remarque : les tableaux de bord de Kubernetes et Jaeger ont un service de type NodePort pour y accéder plus facilement, en utilisant directement le port http du cluster Kubernetes.
Tests de l’application
Une fois l’application déployée, on peut alors y accéder, à partir de l’ip configurée précédemment dans le loadbalancer, ici http://192.168.100.50/productpage.
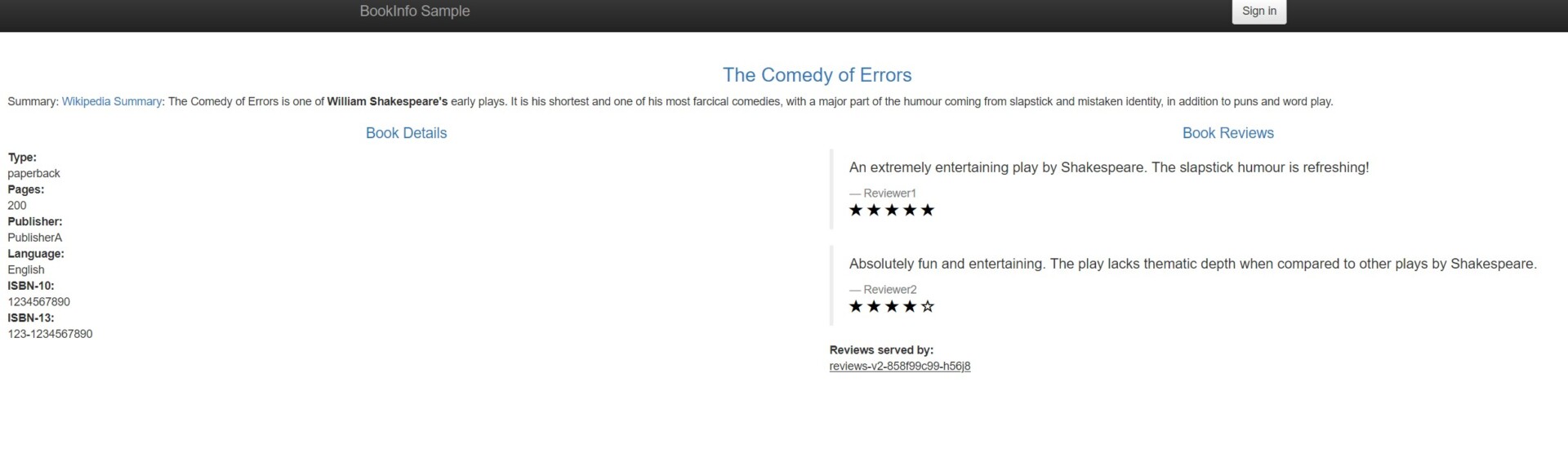
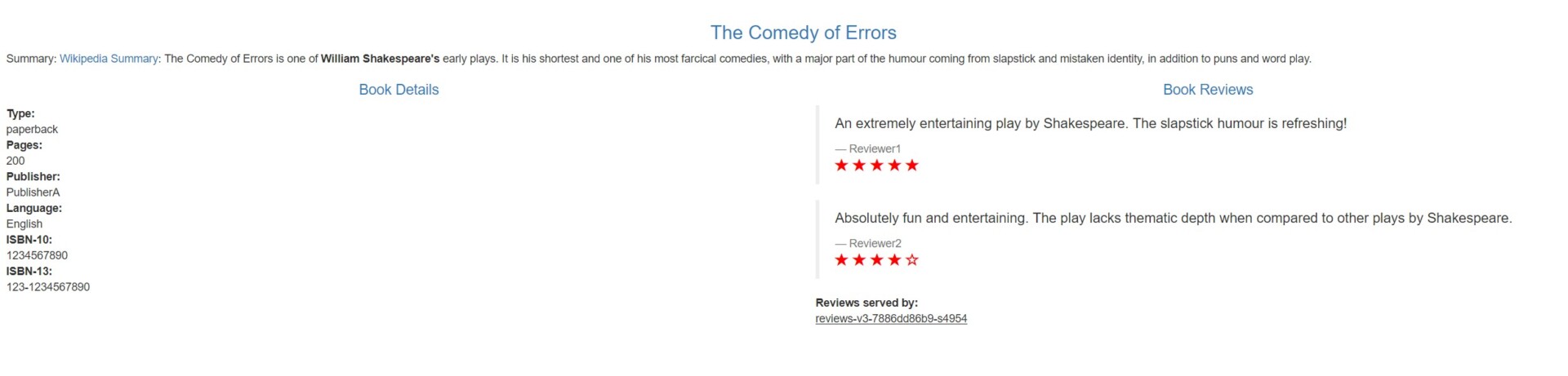
En rafraichissant la page à différents moments, on n’aura pas le même rendu dans la partie Book Reviews. En effet, on est redirigé vers une des 3 versions du service Reviews, ce qui permet de comprendre ce qui se passe au niveau de la request envoyée à l’application. On peut le voir dans le schéma ci-dessous :

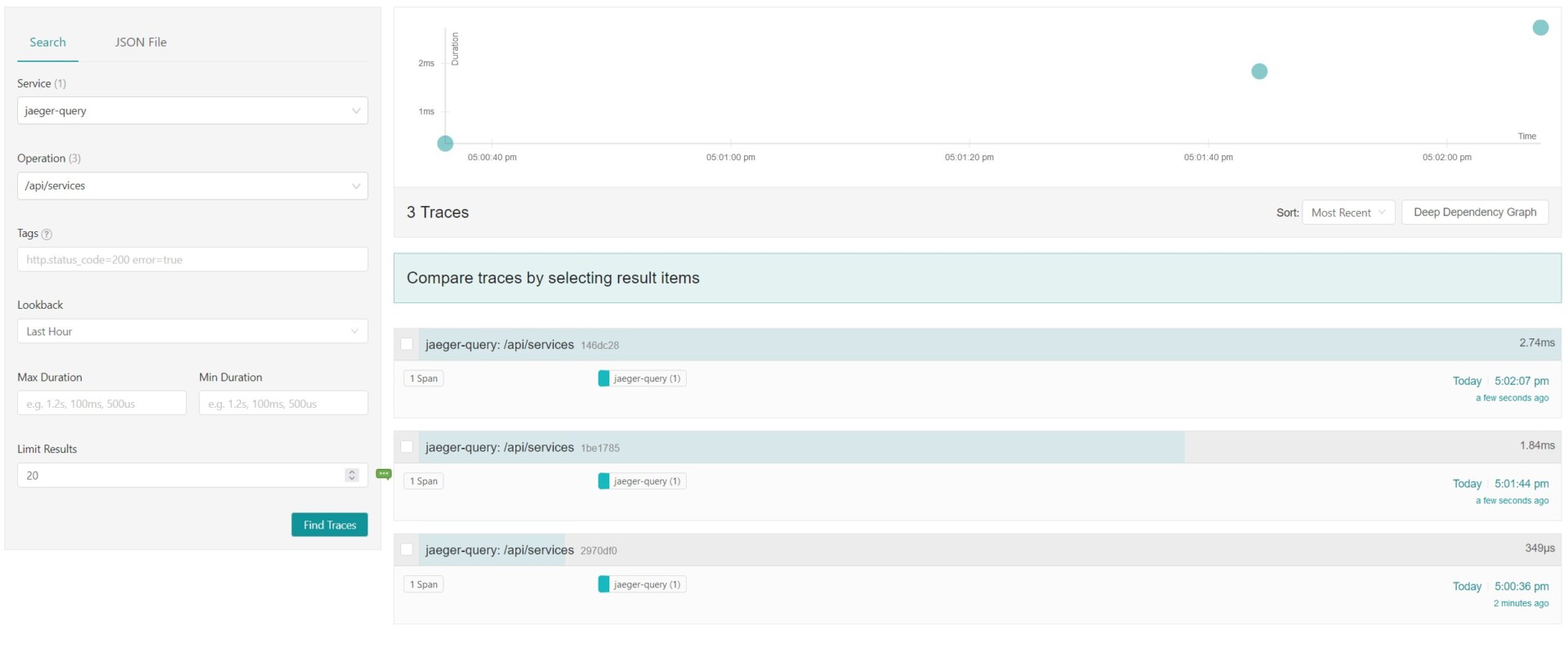
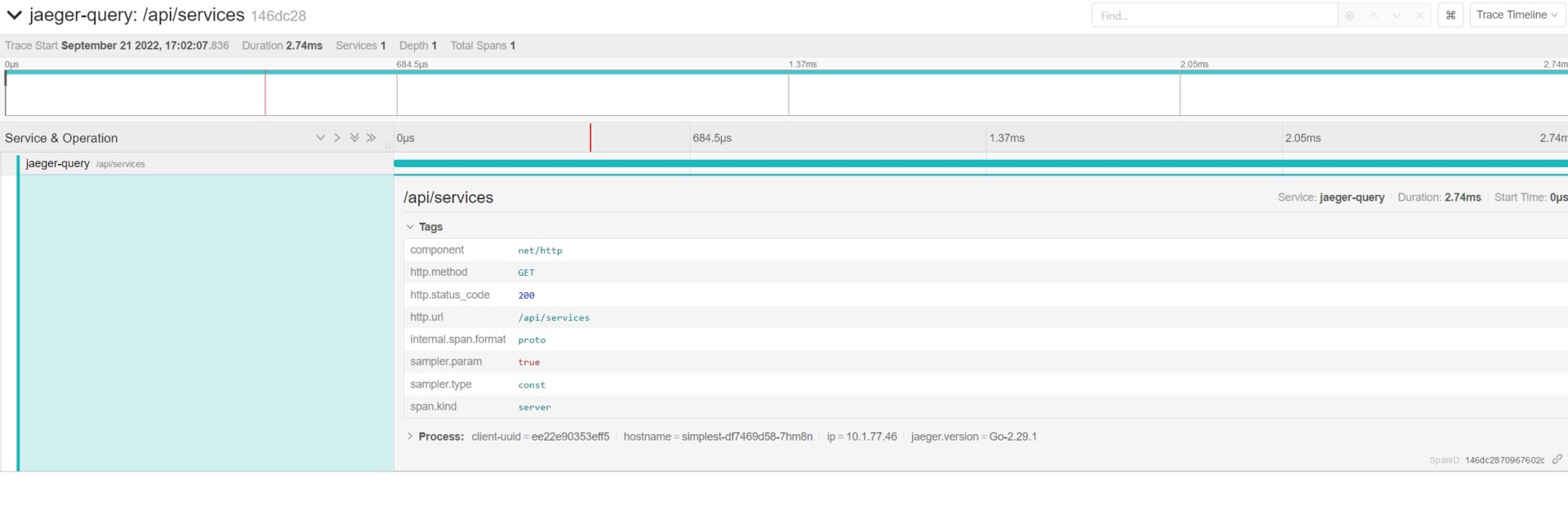
Dans le tableau de bord Jaeger, on retrouve alors les traces du service jaeger-query, avec les tags et spans qui lui sont associés :
Conclusion
Ce retour d’expérience sur l’installation de Jaeger en local, ainsi que sur un cluster Kubernetes, m’a permis d’aborder différentes thématiques tout au long cet article.
Même si le but initial était avant tout de monter en compétences sur la mise en place du tracing dans une application microservices, ce POC m’aura permis de comprendre les notions de bases concernant les données de télémétries.
À travers l’installation de Jaeger sur un cluster Kubernetes, j’ai pu vous partager les choix que j’ai pu faire, que ce soit au niveau de l’infrastructure, des outils à mettre en place, et des briques techniques utilisées pour ce POC.
Si vous aussi, vous souhaitez monter en compétences sur le tracing, je ne peux que vous conseiller d’effectuer votre apprentissage sur un mini cluster Kubernetes, tel que microk8s mais il en existe beaucoup d’autres. Ici l’article se concentrait surtout sur la solution Jaeger, mais l’APM Signoz peut-être aussi un bon point d’entrée, alors lancez-vous !
Sources
Pour découvrir le replay de la conférence Devoxx 2022 de Vincent Behar :
Projets OpenTelemetry, OpenCensus et OpenTracing :
- https://github.com/open-telemetry
- https://github.com/census-instrumentation
- https://github.com/opentracing
- https://www.cncf.io/blog/2019/05/21/a-brief-history-of-opentelemetry-so-far/
Projet Jaeger :
- https://github.com/jaegertracing/jaeger
- https://www.jaegertracing.io/docs/1.23/architecture/
- https://www.aspecto.io/blog/jaeger-tracing-the-ultimate-guide/
- https://hub.docker.com/r/jaegertracing/all-in-one/
jaeger-tutorial : https://github.com/egoebelbecker/jaeger-tutorial.git
OpenZipkin : https://github.com/openzipkin/zipkin
SigNoz : https://github.com/SigNoz/signoz
Tracing : https://tracing.cloudnative101.dev/docs/#_introduction_to_tracing
Microk8s et role Ansible :
- https://microk8s.io/
- https://microk8s.io/docs/addons
- https://github.com/istvano/ansible_role_microk8s
k9s : https://k9scli.io/
kubectx + kubens : https://github.com/ahmetb/kubectx
Istio :
- https://istio.io/latest/
- https://istio.io/latest/docs/tasks/observability/distributed-tracing/jaeger/
Cloud Native Computing Foundation : https://www.cncf.io/
Service Mesh : https://www.redhat.com/fr/topics/microservices/what-is-a-service-mesh
Gradle and Docker : https://codefresh.io/docs/docs/learn-by-example/java/gradle/
Vous avez besoin d’être accompagnés ?
Nos équipes sont à l’écoute !